

Systems detect failure.
They still can't fix it.
Intelligently.
A governed control loop for understanding incidents, choosing the right action, and moving toward resolution safely.
From noisy production signals to
safe executable decisions.
Scrubbe is the control layer missing from modern production systems.
Not alerting · Not monitoring · Not coordination
From raw signal to operational understanding
Every signal is correlated, weighed for confidence and evidence, and surfaced where it changes a decision — across the workspace..
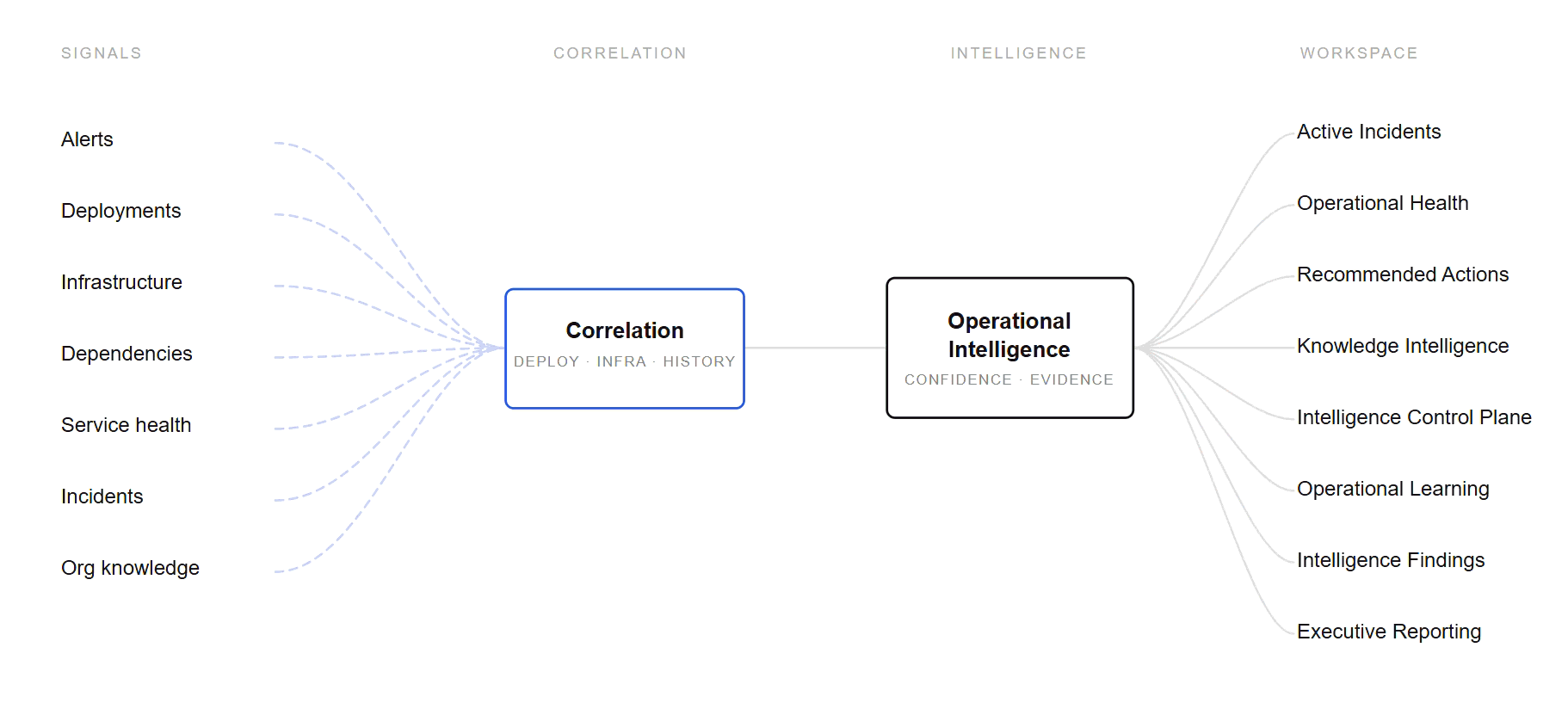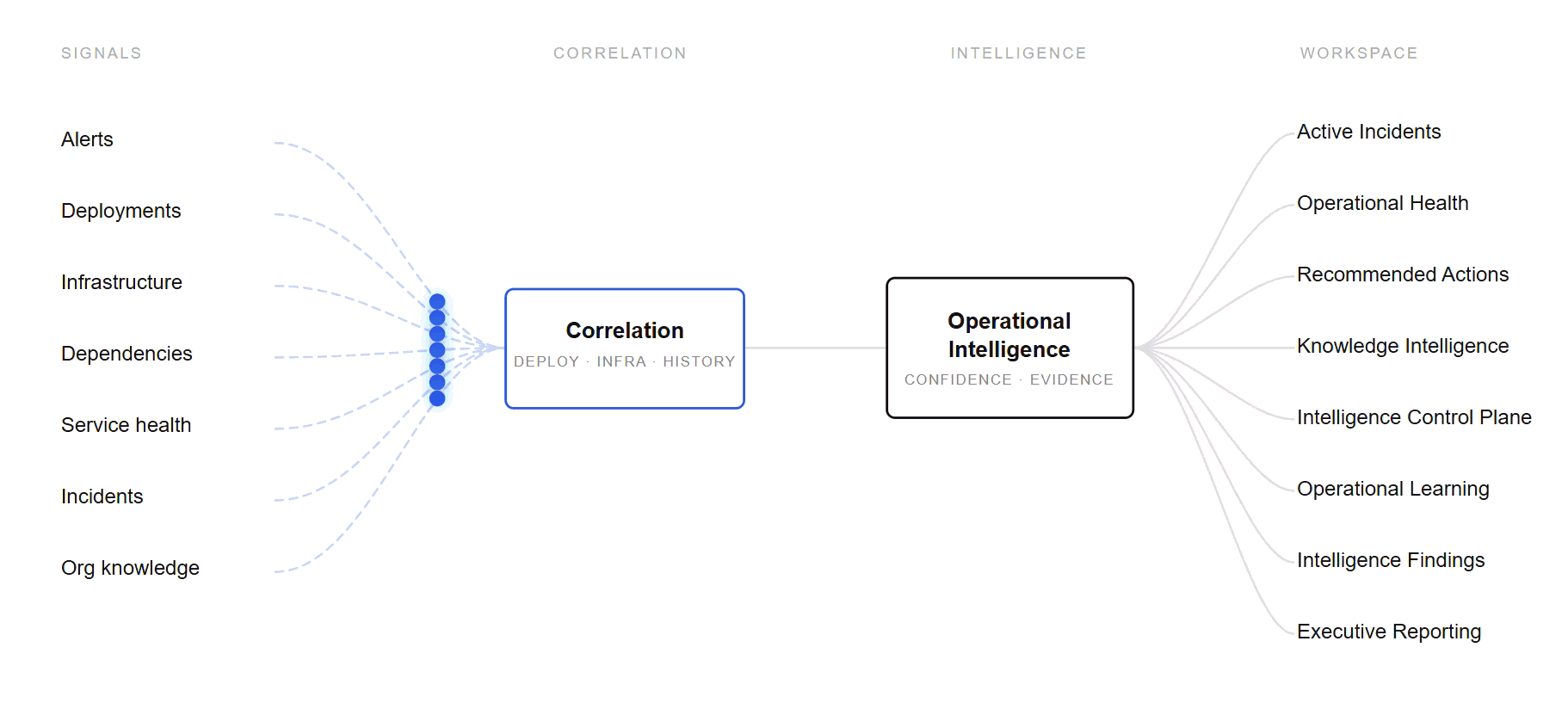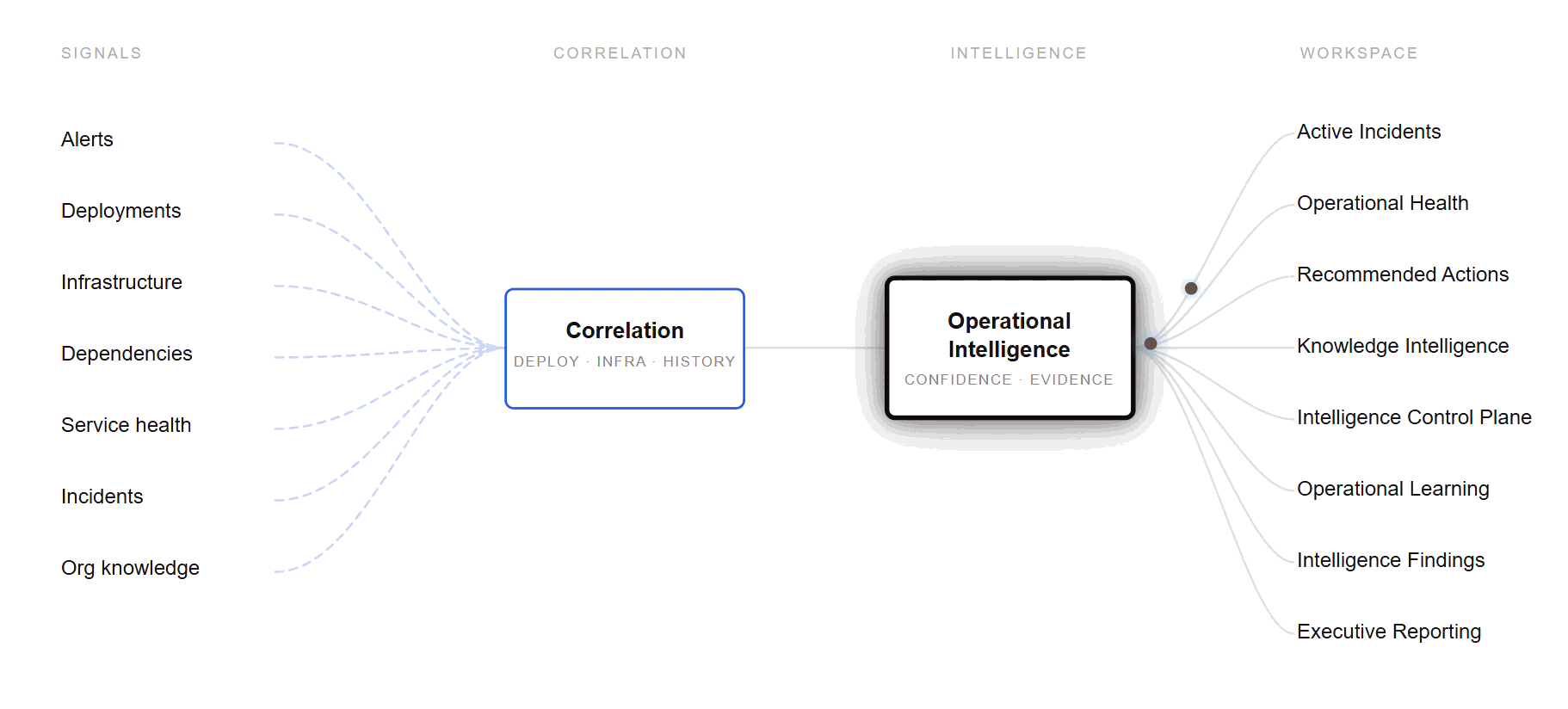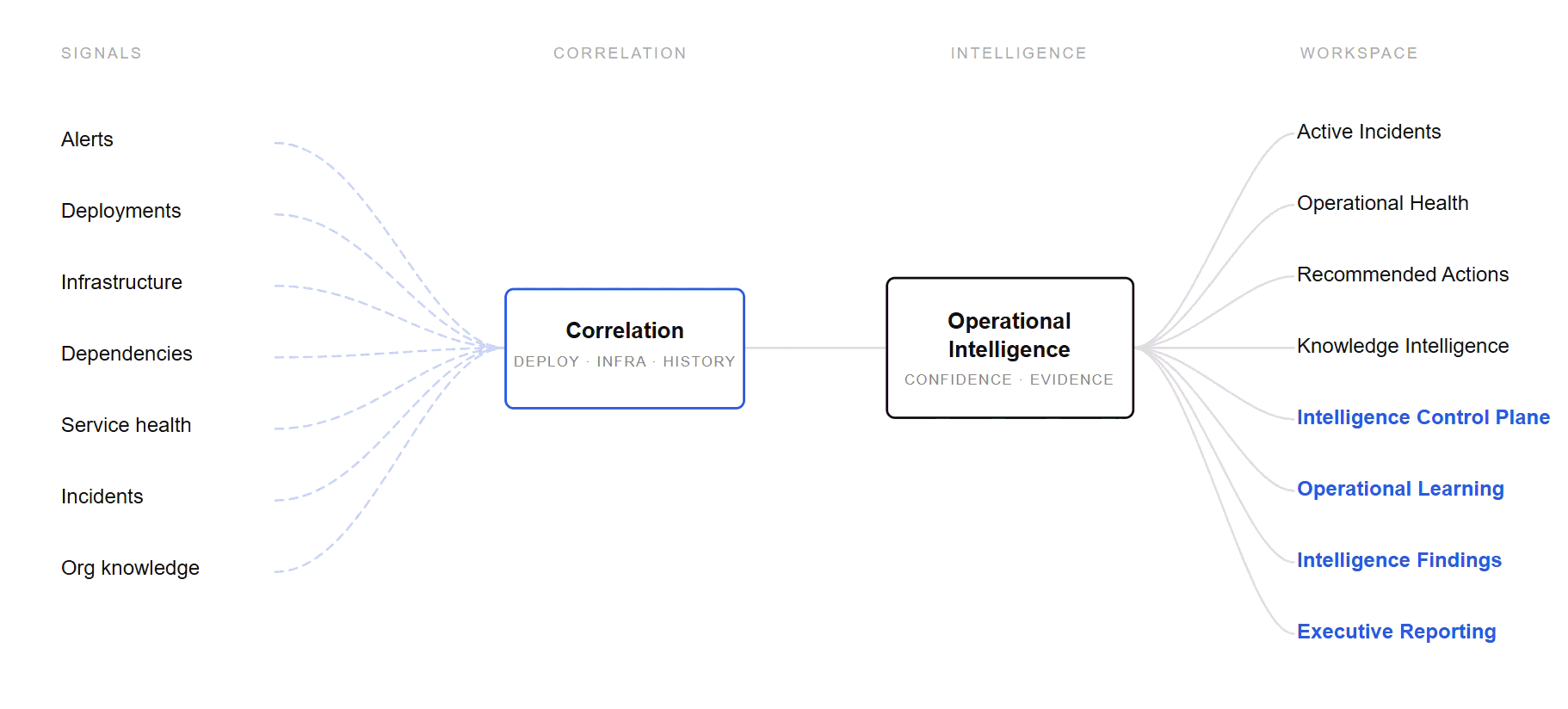
For teams that can detect incidents — but cannot safely resolve them.
Scrubbe is strongest where production failure creates pressure, ambiguity, and execution risk. Choose a user profile to see how Scrubbe fits their workflow.
Platform & Infrastructure Teams
They own production reliability, deployment safety, and cross-service coordination. Scrubbe gives them a control layer that turns operational signals into governed action.
Current pain
Alerts and dashboards still leave teams manually reconstructing cause across services.
How Scrubbe fits
Correlates signals, identifies root cause, generates the safest action, and executes only under policy.
What they gain
Faster resolution with less escalation, lower execution risk, and a reusable incident control loop.
Best trigger
Frequent production incidents across many services, pipelines, and ownership boundaries.
A complete, auditable execution loop.
Scrubbe does not stop at notification or investigation. It carries the incident through understanding, decision, governance, and controlled action.
01
Root cause identified
Signals are correlated into a causal explanation with supporting evidence.
02
Fix generated
A safe remediation path is proposed with confidence and reversibility context.
03
Policy checked
Risk, blast radius, approvals, and execution limits are evaluated before action.
04
Execution completed
Approved remediation runs with full traceability and audit evidence.
A system that replaces manual incident response.
Scrubbe performs the full decision loop under policy: it understands the incident, selects the safest action, validates risk, and executes only when the gate clears.
Detect
Webhooks from GitHub, Kubernetes, Datadog, and PagerDuty arrive simultaneously. Scrubbe absorbs them all and collapses 40 duplicate alerts in 30 seconds into a single incident. Your engineers see one clear signal, not a flood.
Evidence-backed actions, not guesses.
Review actions proposed by Scrubbe agents. Recommendations are generated from deployments, infrastructure telemetry, observability systems, historical incidents, operational playbooks, and organizational knowledge.
Top recommendation · SI-7842
Roll back payments-api to build 2.13.7
Evidence — Error onset +8 min after deploy · matches incident SI-7829 remediation · approval gate required
See the pipeline
in motion.
Watch how Scrubbe takes an incident from raw signal to governed resolution — end to end, no narration required.
Native connectors.
One unified pipeline.
Every integration speaks the same language. Signals from 18 sources are normalised, deduplicated, and evaluated by the same governance layer — so your team gets one incident, not eighteen alerts.

GitHub
Push events, PR merges, failed checks, deployment statuses

Kubernetes
CrashLoopBackOff, pod restarts, OOMKilled, failed deployments

Datadog
Metric alerts, SLO breaches, anomaly detection, monitors

PagerDuty
Alert triggered, incident acknowledged, resolved events

AWS
CloudWatch alarms, ECS task failures, Lambda errors

Prometheus
Alertmanager webhook receiver, rule evaluation events

Gitlab
Pipeline failures, merge requests, job status change

Grafana
Alerting webhooks, dashboard annotations, on-call alerts

Azure
Azure monitor alerts, AKS events, App Service

Google Cloud
Cloud Monitoring alerts, GKE events, Cloud Run errors

Vercel
Deploy intelligence . Application Runtime Signals. Release impact Analysis

Slack
Incident notifications, approval requests, resolution summaries
Built for industries
where downtime costs more
than the fix.
Every sector has a different definition of catastrophic. Scrubbe is architected to handle them all — with the governance depth each one demands.
Financial Services
Milliseconds and compliance.
A payment rail failure measured in seconds produces regulatory reporting requirements measured in months. Scrubbe enforces PCI DSS, SOX, and MiFID II approval chains — architecturally, not through configuration.
→ Payment gateway failures detected in <5s
→ Trading system latency — confidence-scored fix before SLA breach
→ Core banking batch failures gated by Change Manager approval
Avg incident cost reduction
£2.4M/year, tier-1 bank
Healthcare & Life Sciences
When availability is clinical.
Downtime on a clinical decision support system is not a revenue event — it is a patient safety event. Scrubbe's immutable audit trail, RBAC approval chains, and policy versioning satisfy HIPAA and FDA 21 CFR Part 11 by architecture.
→ EHR platform degradation — blast radius includes medication admin
→ DICOM gateway failures gated by CISO approval
→ Full audit chain required for FDA submission support
Compliance coverage
HIPAA · FDA 21 CFRby architecture
E-Commerce & Retail
Revenue per second.
A 60-second checkout failure during Black Friday generates losses no post-mortem can fully account for. Scrubbe's pattern library turns recurring incident classes into solved problems — the same fix that worked last time surfaces in seconds, not 20 minutes.
→ Traffic-triggered DB exhaustion — pattern matched from first occurrence
→ Payment cascade failures — blast radius to checkout mapped instantly
→ Flash sale failures resolved before revenue impact is measurable
Avg MTTR — DB pool exhaustion class
4.2mvs 52m without pattern learning
SaaS & Cloud Platforms
Multi-tenant reliability at continuous scale.
40 deployments per day at 5% incident rate is two incidents a day requiring investigation, remediation, approval, and post-mortem. Scrubbe compresses this cycle. Detection to proposal in under 5 seconds. Approvals in Slack or Teams — no context switching.
→ SLA breach exposure reduced 35–60% for 99.9% uptime commitments
→ Multi-tenant blast radius — enterprise vs free-tier impact distinguished
→ Auth service JWT failures — CASCADE blast radius across all tenants
SLA breach exposure reduction
35–60%for 99.9% commitments
Government & Public Sector
Audit first. Always.
Every change to a citizen-facing system must be documented, attributable, and subject to external audit — not as an afterthought, but as a first-class property. Scrubbe resolves the public sector paradox: the change management process itself is automated, not the changes.
→ GDS standards and NCSC Cyber Essentials documented via audit trail
→ NHS DSP Toolkit compliance baked into guardrail evaluation
→ Retroactive audit queries — no log correlation required
Audit trail completeness
100%every action attributable
Manufacturing & Industrial IoT
OT/IT convergence demands governance.
A software failure in a manufacturing execution system is not an availability event — it is a production stoppage with supply chain and safety implications. Scrubbe permanently enforces Stage 2 approval for any action adjacent to physical systems. No exceptions, regardless of automation settings.
→ MES failures — blast radius maps to assembly line, not just software
→ SCADA integration failures trigger enhanced approval chains
→ Physical-adjacent systems permanently gated — never automated
Physical system governance
Stage 2 min.human approval always
Ready to see it in your stack?
Download the full enterprise ebook — all six domain chapters.
Significant discoveries, surfaced as they emerge
Review operational discoveries identified by Scrubbe — recurring incident patterns, elevated risk indicators, reliability trends, deployment anomalies, infrastructure instability, and emerging areas requiring attention.
This Week
Recurring pattern
Three payments-api incidents in 14 days correlate with configuration changes introduced at deploy time.
Elevated risk
billing-worker risk score reached 91, driven by repeated incident correlation and dependency degradation.
Deployment anomaly
Rollback rate is up 18% week-over-week across delivery pipelines — concentrated in the checkout domain.
One War Room. Total Clarity.
Controlled Execution from Start
to Resolution
Slack War Room
∧Turn Slack into a structured incident command center
Scrubbe transforms Slack channels into live war rooms where engineers and agents collaborate in real time. Context flows directly into the conversation, decisions are visible, and actions are triggered safely—without leaving Slack.

Microsoft Teams War Room
∨Make Teams the single source of truth during incidents
Scrubbe turns Teams into a governed war room where communication, context, and execution come together. Every message, decision, and action is structured, tracked, and controlled—right inside Teams.
Zoom War Room
∨Bring structure and execution into live incident calls
Scrubbe augments Zoom war rooms with real-time context, agent insights, and controlled actions. While teams collaborate live, Scrubbe ensures decisions are captured and execution happens safely alongside the call.
Scrubbe API Section
Programmable
Incident Control.
Build incident automation directly into your stack with Scrubbe's governed API.
Integrate incident intelligence, approvals, investigations, and remediation into your internal tools, CI/CD pipelines, chatops workflows, and monitoring systems.
Scrubbe API gives engineering teams a programmable control plane for incident response — so incidents can be triggered, analyzed, approved, and resolved through code.
Start building with
Scrubbe.
Integrate Scrubbe's code intelligence engine into your project with a single install command
Javascript
npm install @scrubbe/sdk
# or
yarn add @scrubbe/sdk
# or
pnpm add @scrubbe/sdkEzra Code Engine
Intelligence that reads your
code, not just your alerts.
When Ezra identifies a code-level root cause, it surfaces a targeted diff against the affected file — with confidence score, playbook provenance, and a one-click PR to the source repo. Every suggestion is traceable to the incident that triggered it.
0.91
Avg. confidence score
<40s
Suggestion to PR open
100%
Auditable — every suggestion logged
CI · 3 CHECKS FAILED
auth.algorithm.test → FAIL — no algorithm constraint
auth.issuer.test → FAIL — issuer not validated
deploy.version.test → FAIL — header missing
Root Cause Analysis
JWT alg:none attack surface
verifyJwt() called without an explicit algorithm constraint. An attacker can forge tokens using alg:none — bypassing signature verification entirely.
Issues detected
⊗ No algorithm constraint
⊗ Issuer not validated
⊗ Deploy version header missing
Incident
CI Status
3 checks failed
auth.algorithm.test → FAIL
auth.issuer.test → FAIL
deploy.version.test → FAIL
Root cause logged to audit trail
Versioned from day one
All endpoints under /api/v1/. Breaking changes always get a new version — never in place.
Every call audited
JWT identity tied to the audit trail. Not a config flag — enforced by architecture on every request.
Idempotent ingestion
Duplicate events from webhook retries are deduped automatically. No double incidents, no extra work.
5 SDK languages
TypeScript, Python, Go, Ruby, and cURL. All published to native registries with full type coverage.
Migrating from another platform?
Switch to governed incident intelligence.
We'll handle the migration.
Teams switching from PagerDuty, OpsGenie, FireHydrant, Incident.io, Statuspage, and custom in-house tools have a dedicated migration path. Your existing playbooks, escalation policies, and alert routing move across — with full audit continuity from day one.
Cookie preferences
We use essential cookies to keep Scrubbe secure and functional. You can choose whether to allow analytics, preferences, and marketing cookies, and update your choices at any time.
Essential cookies
Required for security, session continuity, consent state, and core site functionality. These are always on.
Analytics cookies
Help us understand usage patterns so we can improve product pages, onboarding paths, and documentation quality.
Preference cookies
Remember selected settings such as region, UI preferences, and previously chosen site options.
Marketing cookies
Enable campaign measurement and more relevant follow-up communications across trusted channels.
Your choices are stored locally in this browser and can be updated at any time from the cookie settings button.